On August 19, Tencent presented their WeChat Mini Games Conference, the first offline WeChat conference this year. Popular games built with the Cocos engine such as "The Strongest Demon Fighter", "Three Kingdoms of Hoolai" and "Mountain and Sea Monsters and Spirit Legends" were presented as well as discussions over improving the performance of mini games, advertising, monetization, and in-app purchases.

One discussion on gameplay introduced as a "Guide to Avoiding Pitfalls" was presented by Tan Jiazhang, the front-end chief engineer from Tencent Photonic Happy Studio. He shared his experience in improving mini game performance and optimization on the "The Strongest Demon Fighter" project to help more developers make more high-quality mini games.
The following is a summary of the speech as well as some slides translated into English for your enjoyment!
Hello everyone! We launched a 2.5D mini game "The Strongest Magic Warrior" this year. Today I will mainly share the technical design and performance optimization techniques used for this game .
Let's briefly introduce our game first. The core gameplay of "The Strongest Magic Warrior" is barrage shooting, and the game map uses a 45-degree angle of view.

Today’s main topic is sharing some specifics on how we built the game. So let me first explain our technical specifications:
"The Strongest Demon Fighter" is a WeChat mini-game and the engine used is Cocos Creator new 3D engine. For the smooth movement of the characters, the protagonist and monsters of the game are made using 3D models. In addition, the game uses a fixed viewing angle, which is mainly to facilitate the combination of 2D and 3D.
From a performance perspective, we actually prefer 2D rendering. In addition to characters and monsters, our other elements such as the surfaces, gold coins, bullets, light effects, and shadows are all rendered in 2D.
One thing worth paying attention to in terms of technology is that the current performance bottleneck of small games due to Apple’s CPU-side performance. More specifically, it is actually due to the inefficiency of JavaScript operations.
In addition, our game itself is also more complicated than most mini-games, the battle logic is complicated, the number of models on the same screen is bigger, and the number of 2D sprites make for a lot of issues for performance. So we set the lowest-end device supported as the Apple iPhone 6s. The performance-related data mentioned later in this talk will be from data we collected from an Apple iPhone 6s.
Today I will share three aspects:
1. Basic design for combat
Hierarchical division of battle scenes
Let's take a look at how we divide our scene levels. The level division has two main goals: one is to better combine 2D and 3D elements, and the other is traditional Drawcall optimization.
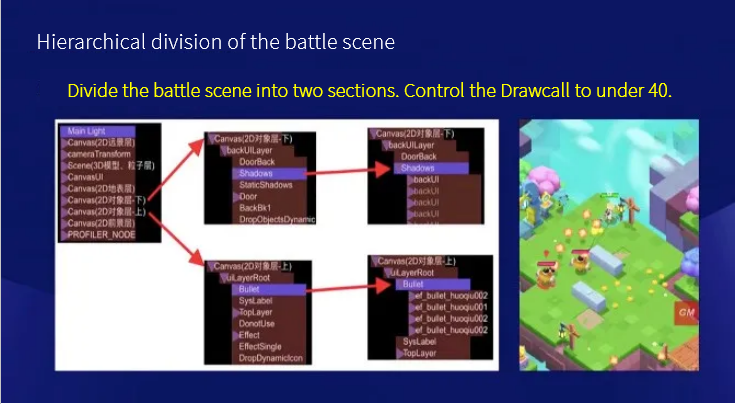
Let's take a look at how we divide our scene levels. The level division has two main goals: one is to better combine 2D and 3D elements, and the other is traditional Drawcall optimization. As you can see from the picture, we divide the top-most node into the distant view layer, the near view layer, and the surface layer. On the surface layer, there are 3D layers containing characters and monsters, and two dynamic 2D sprite layers are placed on the upper and lower ends of the 3D layer, which are subdivided into small layers such as shadows, bullets, numbers, and light effects.
After the division, we restrict each smaller section to use only one texture atlas. In this way, when the engine is rendering the section, it can dynamically synthesize all the sprites in it into a Drawcall for rendering, so that it can better control the Drawcall.
Currently, we have Drawcalls controlled to below 40, which is a relatively small value. But this doesn’t mean the performance is much higher, because it is just one of the necessary optimizations needed.
Rendering of characters and monster models
Take a look at some of our settings in 3D model rendering:

Our 3D model is mainly used for the skeletal animation of the hero and the monster. The two most critical optimization techniques here are GPU skinning and BakedAnimation.
GPU skinning is more commonly used. It transfers complex and time-consuming vertex skinning from the CPU to the GPU layer while BakedAnimation is a caching strategy of the animation system. After the keyframes are cached, each subsequent frame can be rendered. , Without repeated calculations.
The common goal of these two optimization methods is to reduce the CPU operations and as the current bottleneck of the mini game is on the CPU side, their optimization effect is relatively good.
After solving the rendering problem of the single skeletal animation, it is necessary to deal with the situation where the number of simultaneous actions on the screen is too much.
It can be seen from the picture that some of our complex scenes have dozens of models on the same screen at the same time. At this time, the optimization of GPU Instancing technology must be enabled. It can use one Drawcall to render multiple repeated models. In this way, Drawcall and consumption on the CPU side can be controlled relatively low, and it will not increase linearly with the increase of the number of models.
It should be noted that the above optimization methods are actually supported by Cocos Creator 3D engine.
In addition, we also turned off real-time shadows and used 2D sprites to simulate. After some of the above settings, our current model rendering time in combat is about 7ms, which is within an acceptable range.
2. Some targeted optimization solutions
Realization and rendering optimization of the surface
Then take a look at our map. We use small tiles to build in a large map. Its advantage is texture reuse, which can save on download and memory usage.

In order to support the rapid editing of the map, we have developed a special editor. It can be setup so that no matter how big the map is finally edited, the final output resource is a sprite atlas, which can better control the number of our Drawcalls.
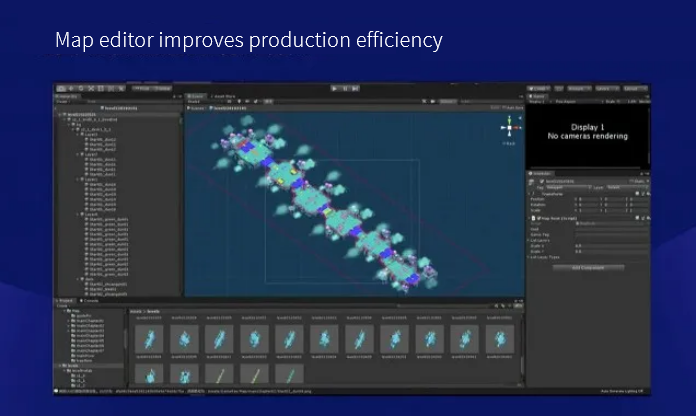
Then what's the problem with the splicing of map blocks? The main problem is that when the number of blocks is large, the rendering pressure will be very high. In "The Strongest Demon Fighter", after removing the nodes outside the scene, the number of blocks on the same screen still reaches more than 300. If you use conventional rendering methods to render, the rendering time will reach 6ms or more, which is unacceptable.
The reason is that it becomes time-consuming because dynamic batching is required when rendering. It needs to traverse all the sprite nodes, then calculate their vertices, UV, IBuff, Color, and other data, and then synthesize a batch to submit for rendering. Although the Drawcall is very low, the amount of computation needed on the CPU side is still very large.

According to the fixed and unchanging characteristics of map tiles, we think that it can be optimized by using static batching. The advantage of static batching is actually to cache the above-mentioned dynamic batching rendering process, and then there is no need to calculate each subsequent frame, just submit the rendering again, and for a specific implementation, the engine also has related components that can be well supported.
After static batching, our rendering time dropped from 6ms to less than 1ms.
Simplified node matrix pre-calculation
In addition to the static map blocks mentioned above, there are a large number of dynamic nodes in our scene, such as bullets, light effects, health bars, shadows, etc. seen in the screenshot. The number of them is very large, there can be more than 100 of them at one time. Each 2D sprite itself is in a certain container structure, so there are actually more nodes in motion in the scene than the number of sprites we see.

Through our statistics, we found that there will be more than 600 nodes in the most complex level at the same time. What problems could there be with such a large number of nodes? The main issue is that the matrix operation of the nodes will take more time.
The Cocos engine node calculates the transformation through a matrix, which is also the most common way of implementation. The advantage is that it can fully support translation, zoom, and rotation. The disadvantage is that it is more complicated, especially when calculating in JavaScript.

Is there any way to optimize such a large number of matrix operations? A key point here is that most of the nodes in the scene do not need to support rotation, but only need to do displacement and scaling. Rotation is the most complicated piece of matrix operations.
So, we will see a point that can be optimized from here. Our approach is as follows: Based on the previous assumptions, we modify the logic of the engine's calculation node transformation and remove the matrix operation of the calculation position. Replaced with a simple sum and product operation, which can support displacement and scaling, and also calculate the final position of the node.

This optimization is effective for 80% of the nodes in the scene, so the effect is better, and the time consumption can be reduced by one to two milliseconds in complex levels.
Optimization of node addition and deletion performance
As mentioned earlier, the number of nodes is very large. In addition to the matrix operation consumption, there is also a performance problem of node addition and deletion that you have to pay attention to.

In the design of the Cocos node tree, adding and deleting nodes has a certain performance cost. When the number of nodes being added and deleted at the same time is large, this cost is very prominent.
"The Strongest Magic Fighter" is at times a bullet hell game. The number of nodes is added and deleted frequently can get very large. For example, at certain moments, we will have dozens of bullets created, and dozens of bullets will disappear at the same time. Adding special effects, like the creation and disappearance of shadows, can have more than 200 node additions and deletions occurring in a frame in a complex level. Then the computing peak brought by the addition and deletion of this node is enough to bring about a sharp drop in the frame rate, and bring the user a poor experience.
The addition and deletion of nodes is not a continuous consumption, so it is not obvious in the average frame rate, so it is easy to be ignored because of this.
How can we optimize this problem? The method we use is lazy additions and deletions. That is, once a node is added to the number of nodes, we no longer remove it. When we want to hide the node, we use a lightweight method to replace the engine's interface, such as setting a hidden attribute in the node, and then modify the engine's rendering process. When we encounter these hidden nodes, we skip them so that we can hide the nodes.
After this modification, our node additions and deletions basically do not consume much, and there will be no budget peaks and stalls.
3. Final Thoughts
Finally, let me share our bottleneck analysis methods and some future thoughts.
First of all, performance optimization. Our focus is actually on Apple devices. Then, it is currently impossible to run Profile on Apple devices, so this brings us some challenges.

How do you optimize the frame rate in Apple devices? I recommend a dumb method here. Let's do some time-consuming statistics in the main loop of the engine or our logical main entrance. This is the total time-consuming of a big loop. Then during the running process, we dynamically switch some nodes and functions, and then calculate the time consumption of the subsystem through the change of the total time consumed.
The advantage of this method is its simplicity. It is accurate for some coarse-grained performance consumption statistics. The disadvantage is also that it cannot do more fine-grained analysis, such as the inability to locate specific functions.
In addition, you can also run Profile on PC and Android, and sometimes you can locate some computing hotspots. However, if you run Profile on the PC, the hotspot distribution reflected by it is not exactly the same as that on Apple devices, so be careful not to be misled here.
Here are some of the tools we made:

On the left is the node management tool, which can display all the current nodes of the entire scene when it is running, and then dynamically disable and activate the nodes. It is mainly used to evaluate the rendering time of a certain type of node, such as skeletal animation. It’s a bit time consuming.
On the right are some GM tools, which can switch some of our business logic, such as stopping collisions and suspending monster behaviors.
After the above analysis, we can get a time-consuming distribution map of the entire game.

It can be seen that after a round of optimization, the current time-consuming part is the model rendering and battle logic. The total time-consuming reaches 25 milliseconds, so it can only run to about forty frames on the Apple 6s.
How to further optimize it in the future? I think that in addition to a better solution, Apple may also need to provide more sophisticated optimization tools on the platform side, otherwise our bottleneck analysis efficiency is very low.
In the future, it is worth noting that Worker threads can be used to relieve the pressure on the main thread. One of the things we are doing is to transfer our combat logic to the Worker as a whole.
As you can see from the figure, if we complete this migration, our main thread consumption can be greatly reduced, about 28%. But here we also need to balance the migration cost of this logic and the communication cost of the worker itself.
That’s all I can share with you today. Thank you all for listening!






